




在无约束环境下,人脸姿态、光照、年龄变化给人脸识别任务带来巨大挑战。传统CNN感受野受限,纯Transformer又存在计算冗余、依赖大数据训练等短板。近日,阿尔及利亚奥兰科技大学、西班牙卡塔赫纳理工大学研究团队联合推出融合残差网络与膨胀上下文Transformer注意力(DCoT)的人脸识别新模型,相关成果发表于IETBiometrics。

DOI:https://doi.org/10.1049/bme2/7309163
本研究由Randa Nachet、Tarik Boudghene Stambouli主导,通讯作者JavierGarrigós来自西班牙卡塔赫纳理工大学电子与计算机技术系。团队以轻量化ResNet34为骨干,兼顾表征能力与计算开销,系统对比自注意力SA、上下文Transformer注意力CoT以及自研DCoT三种机制。
核心创新在于膨胀上下文Transformer注意力DCoT:通过空洞卷积扩大感受野,在不显著增加参数量与计算量的前提下,捕获更丰富人脸全局上下文信息;同时保留局部空间特征,精准聚焦眉眼口鼻等判别性关键区域。团队还引入深度可分离卷积,将模型参数量从21.55M压缩至17M,实现精度与轻量化的完美平衡。 FIGURE 1 | (a) The overall architecture of the proposed face recognition framework, based on ResNet34. The attention mechanism is integrated into the head output. (b) The modified residual block within the framework. 实验基于CASIA-WebFace数据集训练,在LFW、CPLFW、AgeDB_30等权威基准上全面验证。消融实验证明,DCoT dilation率取2时性能最优,LFW数据集准确率高达99.60%,大幅超越原始ResNet34基线模型;在跨姿态、跨年龄等复杂测试集上,性能也优于S-ViT、FIN-TinyV2等主流模型。Grad-CAM可视化与ROC曲线进一步证实,DCoT能抑制背景干扰、强化人脸特征表征,低误报场景下验证稳定性极强。 FIGURE 2 | Comparison of attention mechanisms. (a) Standard self-attention mechanism. (b) Contextual transformer attention mechanism, which focuses on local regions. (c) Dilated contextual transformer attention mechanism, which expands the receptive field, allowing the model to capture more global contextual information. 此外,论文还剖析了模型失效案例,极端姿态偏转、面部遮挡仍是难点,也为后续优化指明方向。未来团队将把DCoT拓展至ResNet50/101深层骨干,并在更大规模人脸数据集上验证泛化能力。 FIGURE 3 | Training curves across epochs: (a) Training loss and (b) LFW validation accuracy for the baseline model and attention variants.


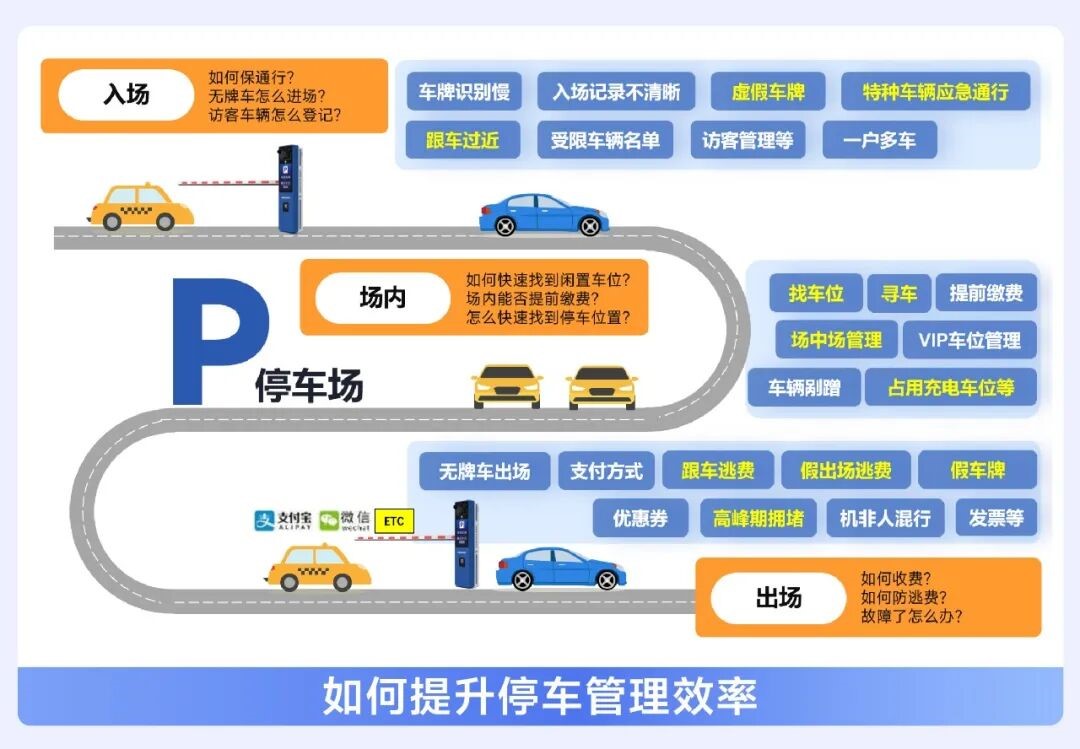 提升车主体验,提高管理效率,海康威视停车产品有话说
提升车主体验,提高管理效率,海康威视停车产品有话说 熵基科技:何以坐稳门禁界的 “王者” 宝座?
熵基科技:何以坐稳门禁界的 “王者” 宝座? 停车杂牌终结者来了!捷顺科技1688旗舰店开业,一线品质直通千城万镇
停车杂牌终结者来了!捷顺科技1688旗舰店开业,一线品质直通千城万镇









精彩评论